|
I am a graduate student at Mila. I am advised by Prof. Sarath Chandar and Prof. Irina Rish.
I am passionate about building general intelligence. I am specifically interested in Highly Multimodal Models, Reasoning,
Planning, Memory, Foundation Models, Embodied Agents and Scaling Laws.
|

|
|
|
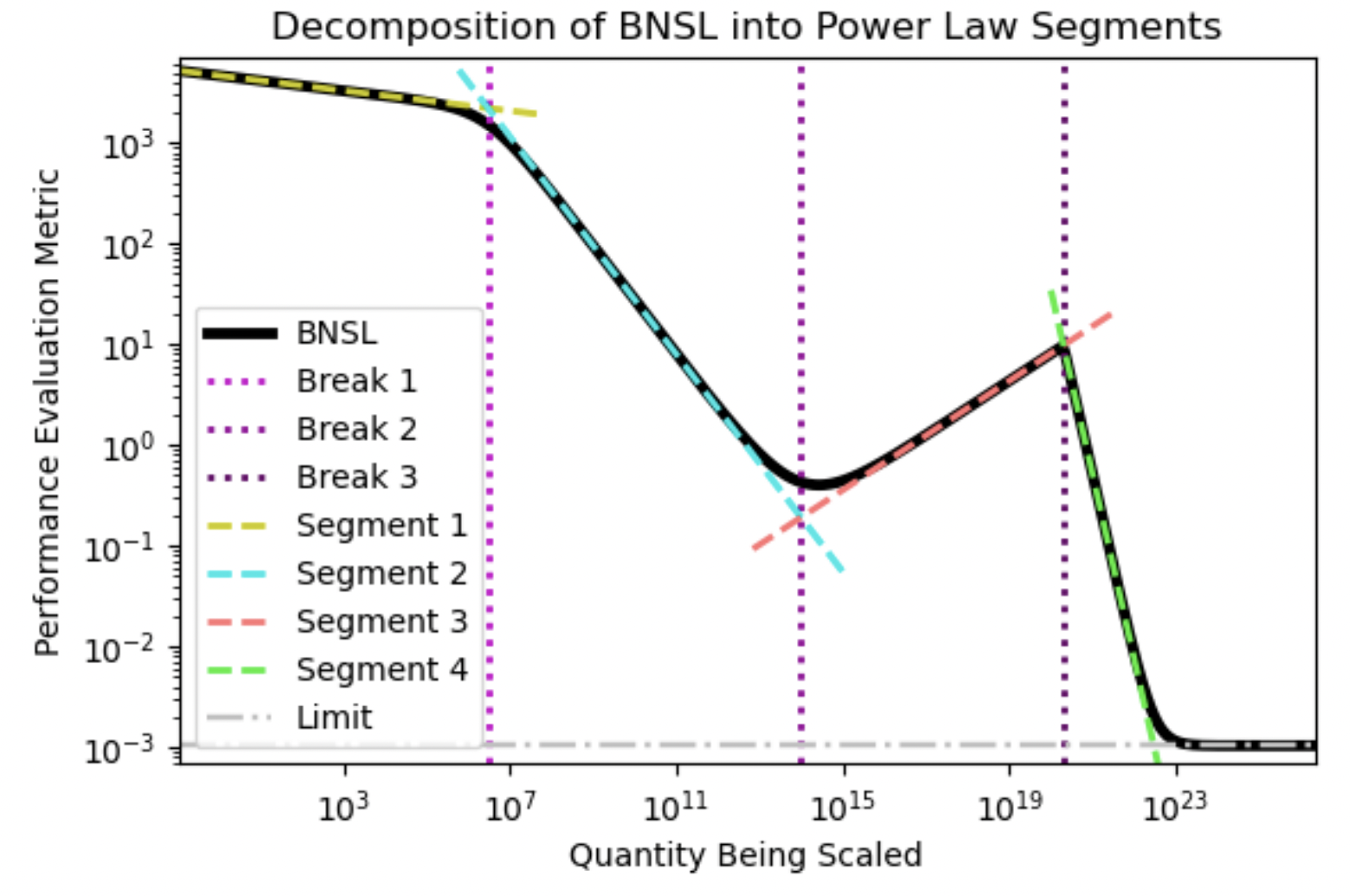
Ethan Caballero, Kshitij Gupta, Irina Rish, David Krueger Project Code We present a smoothly broken power law functional form that accurately models and extrapolates the scaling behaviors of deep neural networks (i.e. how the evaluation metric of interest varies as the amount of compute used for training, number of model parameters, training dataset size, or upstream performance varies) for each task within a large and diverse set of upstream and downstream tasks, in zero-shot, prompted, and fine-tuned settings. This set includes large-scale vision and unsupervised language tasks, diffusion generative modeling of images, arithmetic, and reinforcement learning. When compared to other functional forms for neural scaling behavior, this functional form yields extrapolations of scaling behavior that are considerably more accurate on this set. Moreover, this functional form accurately models and extrapolates scaling behavior that other functional forms are incapable of expressing such as the non-monotonic transitions present in the scaling behavior of phenomena such as double descent and the delayed, sharp inflection points present in the scaling behavior of tasks such as arithmetic. Lastly, we use this functional form to glean insights about the limit of the predictability of scaling behavior. |
|
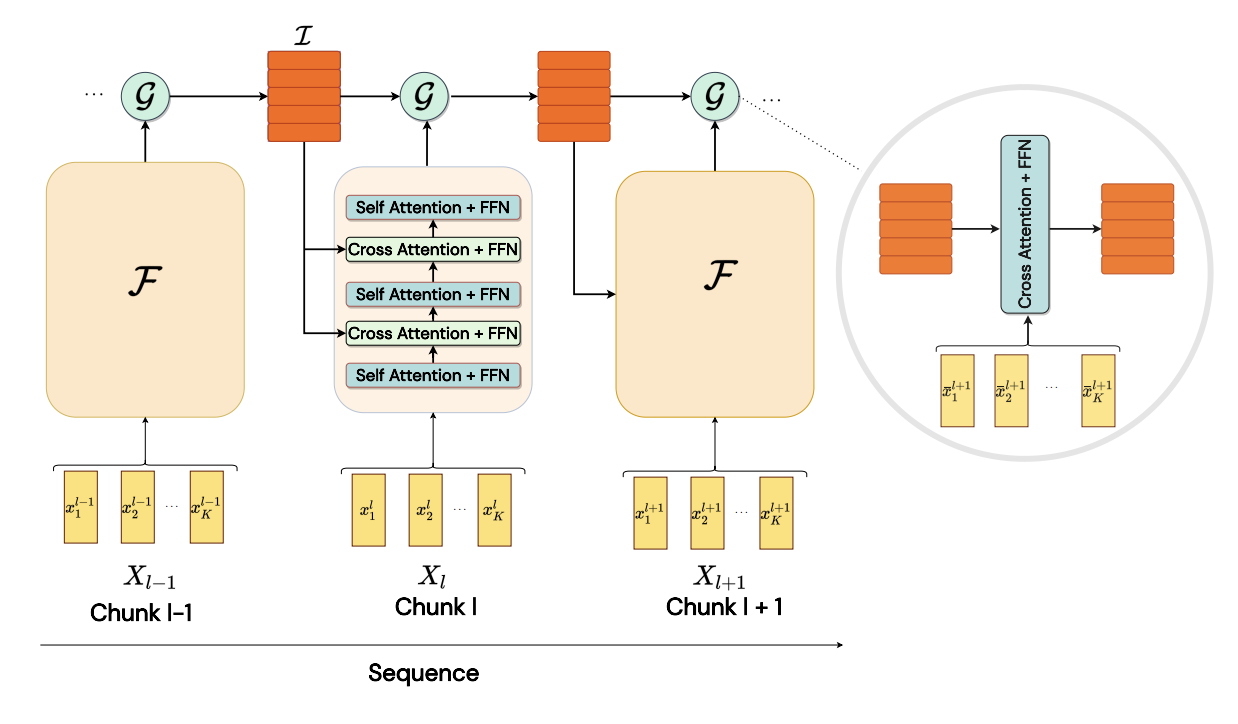
Aniket Didolkar, Kshitij Gupta, Anirudh Goyal, Nitesh B. Gundavarapu, Alex Lamb, Nan Rosemary Ke, Yoshua Bengio Recurrent neural networks have a strong inductive bias towards learning temporally compressed representations, as the entire history of a sequence is represented by a single vector. By contrast, Transformers have little inductive bias towards learning temporally compressed representations, as they allow for attention over all previously computed elements in a sequence. Having a more compressed representation of a sequence may be beneficial for generalization, as a high-level representation may be more easily re-used and re-purposed and will contain fewer irrelevant details. At the same time, excessive compression of representations comes at the cost of expressiveness. We propose a solution which divides computation into two streams. A slow stream that is recurrent in nature aims to learn a specialized and compressed representation, by forcing chunks of $K$ time steps into a single representation which is divided into multiple vectors. At the same time, a fast stream is parameterized as a Transformer to process chunks consisting of $K$ time-steps conditioned on the information in the slow-stream. In the proposed approach we hope to gain the expressiveness of the Transformer, while encouraging better compression and structuring of representations in the slow stream. We show the benefits of the proposed method in terms of improved sample efficiency and generalization performance as compared to various competitive baselines for visual perception and sequential decision making tasks. |
|
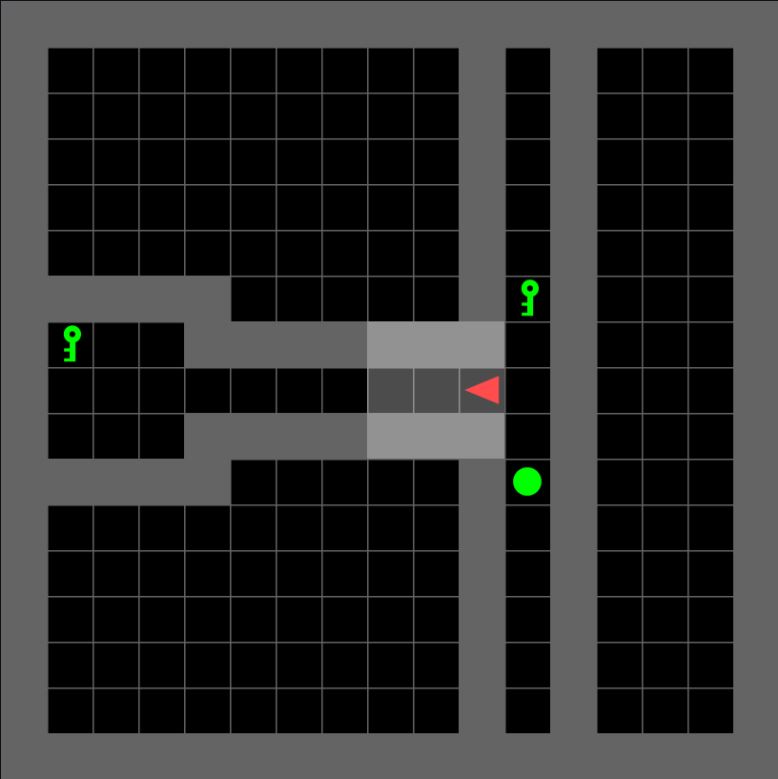
Kshitij Gupta Project Report In this work, we study and demonstrate the importance of various design decisions for Recurrent PPO in partially observable domains with long episodes and in continuing tasks. We also show that simple strategies like updating hidden states (before collecting new experience) and recomputing hidden states (before each epoch in minibatch gradient descent) can prevent staleness in updates and significantly improve performance. Finally, we provide practical insights and recommendations for implementing Recurrent PPO. |
|
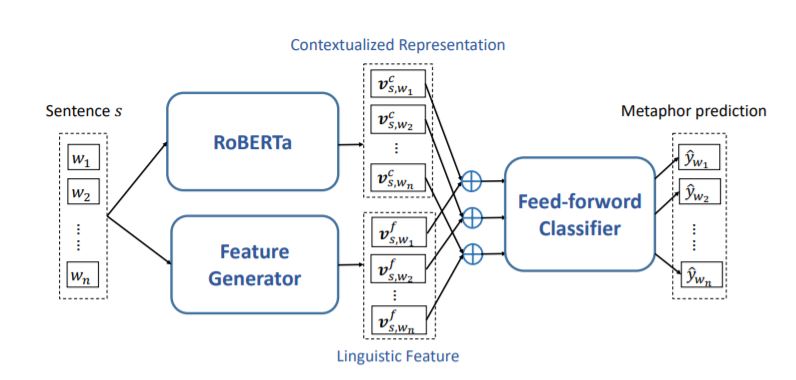
Hongyu Gong, Kshitij Gupta, Akriti Jain, Suma Bhat ACL, 2020 Paper We present IlliniMet, a system to automatically detect metaphorical words. Our model combines the strengths of the contextualized representation by the widely used RoBERTa model and the rich linguistic information from external resources such as WordNet. |
|
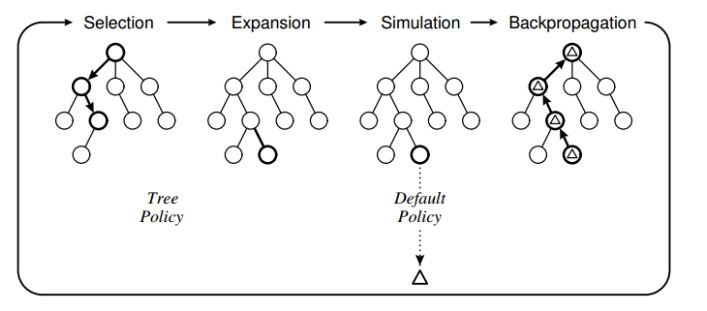
Kshitij Gupta, Jeffrey Lai, Keshav CS 498, IR Model-based RL has a strong advantage of being sample efficient. Once the model and the cost function are known, we can plan the optimal controls without further sampling. We explore various model based planning methods and experiment on various Gym Environments. |
|
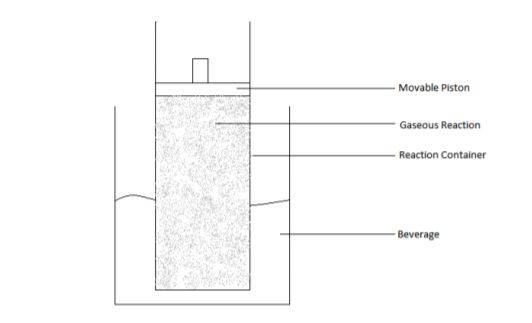
Kshitij Gupta IJIRSET, 2016 Paper This paper explores the use of reversible endothermic gaseous chemical reactions to create a truly portable, reusable instant cooler that is human powered. |

|
|

|
|

|

|

|
|
DeepMind Summer 2022 |
Microsoft Summer 2021, . Summer 2020, Summer 2019 |
CS@Illinois: Koyejo Labs, July 2020 - Dec 2020 |
C3SR:URAI Scholar September 2019 - May 2020 |
CSL Jan 2020 - Sep 2020 |
CSS Corp Summer 2018 |
eRx Solutions Summer 2017 |
|
|
Template Credits Jon
Barron Unnat
Jain
|